Scheduled Views Best Practices and Examples
A Scheduled View reduces aggregate data down to the bare minimum, so they contain only the results that you need to generate your data. Queries that run against Scheduled Views return search results much faster because the data is pre-aggregated before the query is run. Scheduled Views process queries once per minute.
These items are required in Scheduled View queries:
- Always use an aggregate operator. This will allow you to avoid duplicating data.
- Always run an aggregation by a timeslice operator. If you don't, Receipt Time will be used.
Also, keep the following things in mind when you're creating Scheduled View queries:
- Avoid using queries that are likely to change. A key benefit of using Scheduled Views is that they can index historical data, allowing you to identify long-term trends. If a query changes, you may lose some of the historical perspective.
- Keep the query flexible. Using a flexible query, like
_sourceCategory=*Apache*so that metadata changes don't break the query. - Consider using fields with more general values (fields with less specificity). For example, you'd want to use "country" and "city" fields instead of "latitude" and "longitude".
- Use Partitions. Partitions allow you to reduce your query time even more.
- Access historical data. Your Scheduled View can go as far back as your retention period.
- Use more groups. Plan for flexibility by including more groups. However, test your Scheduled View definition to understand how much additional data that extra groups will create.
What types of operators are supported in Scheduled Views?
Scheduled Views are defined by a query, with the search results being indexed.
Due to the way data is indexed in Views, only the following operators are supported:
Non-aggregate operators
- Ceil
- Concat
- CSV
- Fields
- Format
- FormatDate
- Geoip
- JSON ('auto' option is not supported)
- Keyvalue
- Length
- Lookup
- Matches
- Now
- Parse
- Parse regex, or extract
- Predict
- Replace
- Round
- Substring
- Threatip
- Timeslice (less than 1 day)
- ToInt/ToLong
- Where
- Withtime
Do not use the Pct or Avg operators: they do not yield accurate results. Because the query only runs over a one-minute time range (every minute), there are not enough data points to give an accurate sampling.
Aggregate operators
- Count
- Min
- Max
- Sum
Scheduled View Validation
Scheduled View validation works this way:
- If the query is a non-aggregate query, then only operators from the non-aggregate list are allowed.
- If the query is an aggregate query, then all of the operators before the first "group by" statement must be non-aggregate. Then all operators are allowed after the first "group by" operator.
The following operators do not yield reliable results when used against a Scheduled View, but below are some alternative methods to obtain values:
Average
This can be calculated by taking the sum over timeslices and dividing by the total count.
Original Search:
_sourceCategory=mySourceCategory "literal search term"
| parse “seconds = *,” as seconds
| avg(seconds)
Scheduled View Definition:
_sourceCategory=mySourceCategory "literal search term"
| parse “seconds = *,” as seconds
| timeslice 1m
| sum(seconds) as secondspertimeslice,count as countpertimeslice by _timeslice
Query:
_view=myScheduledView
| sum(secondspertimeslice) as totalseconds, sum(countpertimeslice) as totalcount
| totalseconds / totalcount as theaverage
Other Operators
Count_Distinct, First, Last, Min, Max, Most_Recent, Least_Recent, Pct, Stddev, "Math Values", and RollingStd.
Create the Scheduled View with a count operator to count by the fields you want to aggregate with instead of the unsupported operator. Then you can reference the View and run the aggregation you want.
For example, if you want to create a Scheduled View with most_recent:
_sourceCategory=receiver
| parse "dataPointCount=*)" as points
| parse "remote_ip=*]" as ip
| withtime points
| most_recent(points_withtime) as last_result by ip
Remove the unsupported operation, most_recent, and instead create a Scheduled View with the count operator:
_sourceCategory=receiver
| parse "dataPointCount=*)" as points
| parse "remote_ip=*]" as ip
| withtime points
| count points_withtime, ip
If the View's name was Points you can use the most_recent operator against the View:
_view=Points
| most_recent(points_withtime) as last_result by ip
Scheduled View Examples
Below are a few examples of queries that can be optimized with a Scheduled View. The original search, the Scheduled View definition, and the query that can be run on the Scheduled View are all shown.
Pre-Aggregating Data
Original Search:
_sourceCategory=mySourceCategory "literal search term"
| parse "[clientip *]" as clientip
| if (clientip matches "*-*","timeout","slow") as type
| timeslice 1h
| count as value by _timeslice, type
Scheduled View Definition:
_sourceCategory=mySourceCategory "literal search term"
| parse "[clientip *]" as clientip
| if (clientip matches "*-*","timeout","slow") as type
| timeslice 1m
| count as value by _timeslice, type
Query:
_view=myScheduledView
| timeslice 1h
| sum(value) as value by _timeslice, type
Improving Search Performance
Original Search:
_sourceCategory=iis_logs | parse "* * 192.* " as date,time,internalip
Scheduled View Definition:
_sourceCategory=iis_logs | parse "* * 192.* " as date,time,internalip
Query:
_view=myScheduledView2
Notice the parse statement will drop any log entries that do not contain the 192.* internal IP string from the _sourceCategory. This will create a smaller subset of data that may be more appropriate for a Scheduled View. If you were searching through all of the IIS logs on a regular basis, a partition may be a better solution to improve query performance.
Lightweight vs Robust Scheduled View
This Scheduled View query is lightweight, and contains only one group:
_sourceCategory=prod/web/iis | timeslice 1m | count by _timeslice
which would produce results like:

Compared to this Scheduled View query, which is more robust, but five times heavier with one additional column:
_sourceCategory=prod/web/iis | timeslice 1m | count by _timeslice, status_code
This would produce results like:
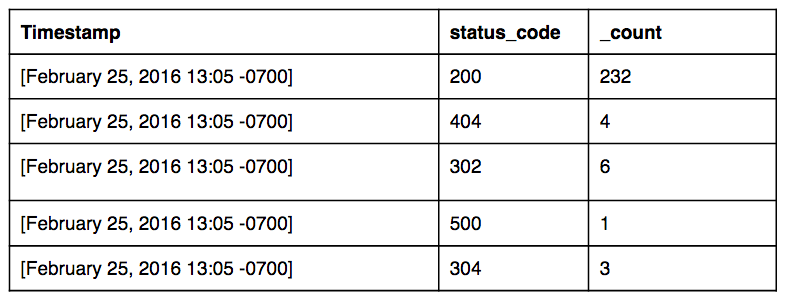
Now you can use sum on your records, because the counts are broken out. For example, use the sum operator to aggregate the aggregation in the following query:
_view=nice_view_man | timeslice 1d | sum(_count) by _timeslice, status_code